

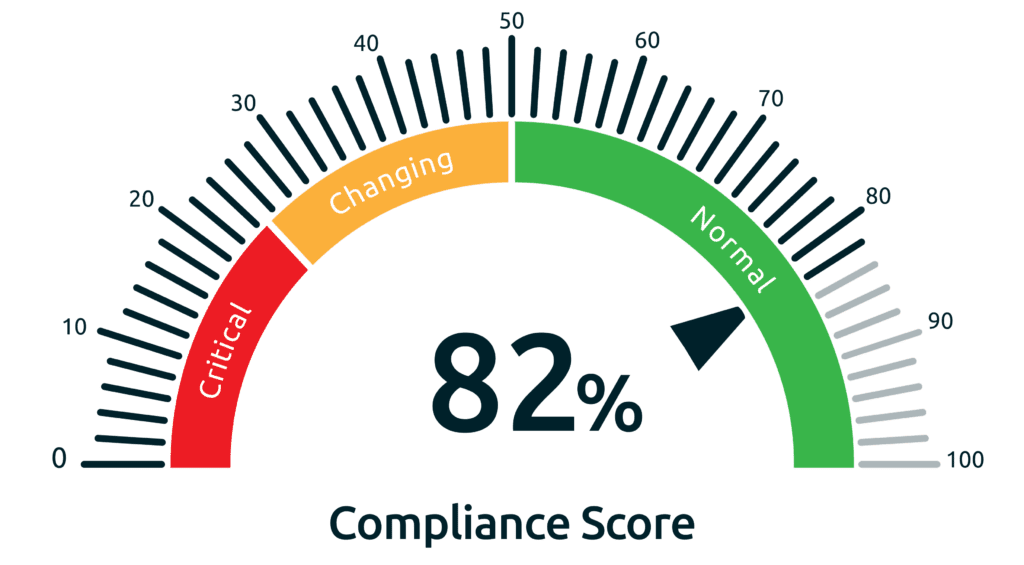
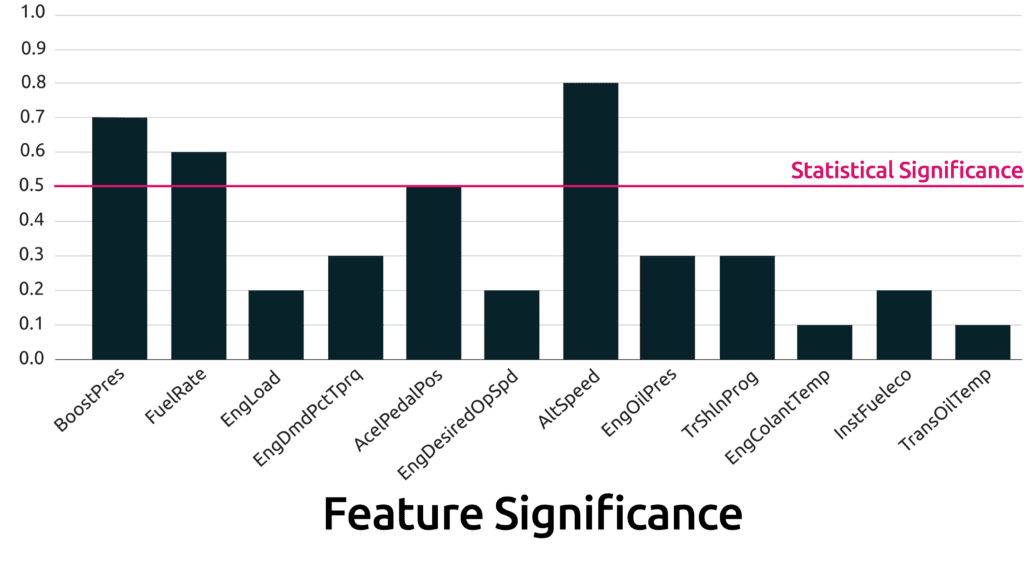
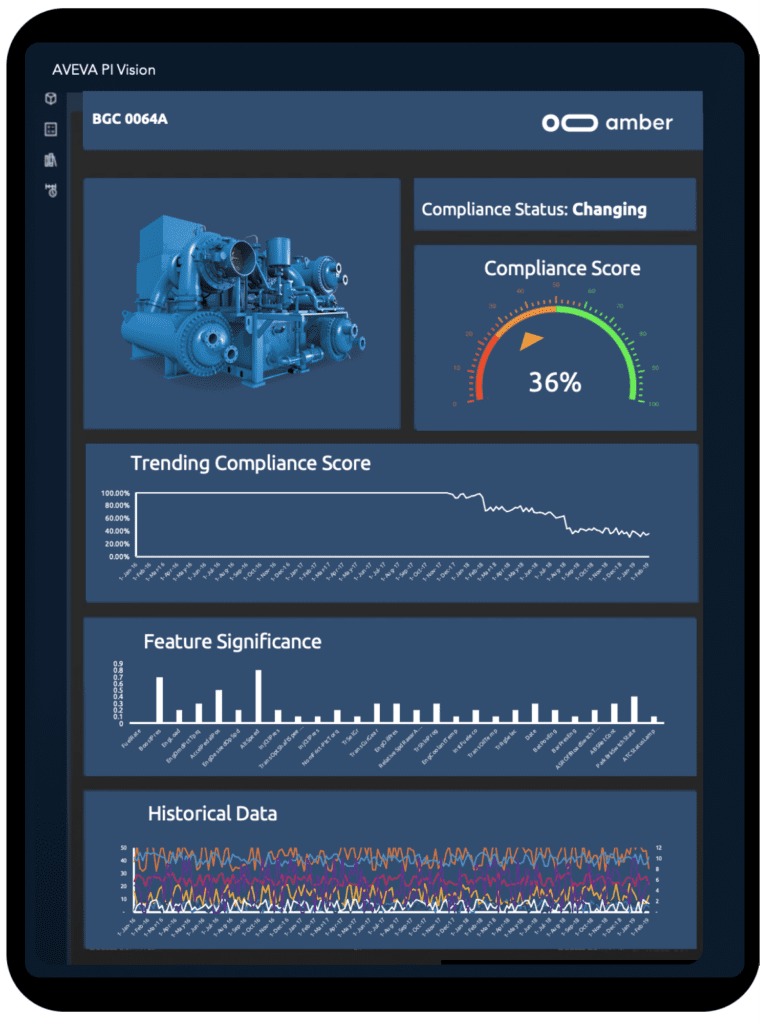
Accurate prediction
Detect early signs of failure as soon as they occur without annoying false alarms

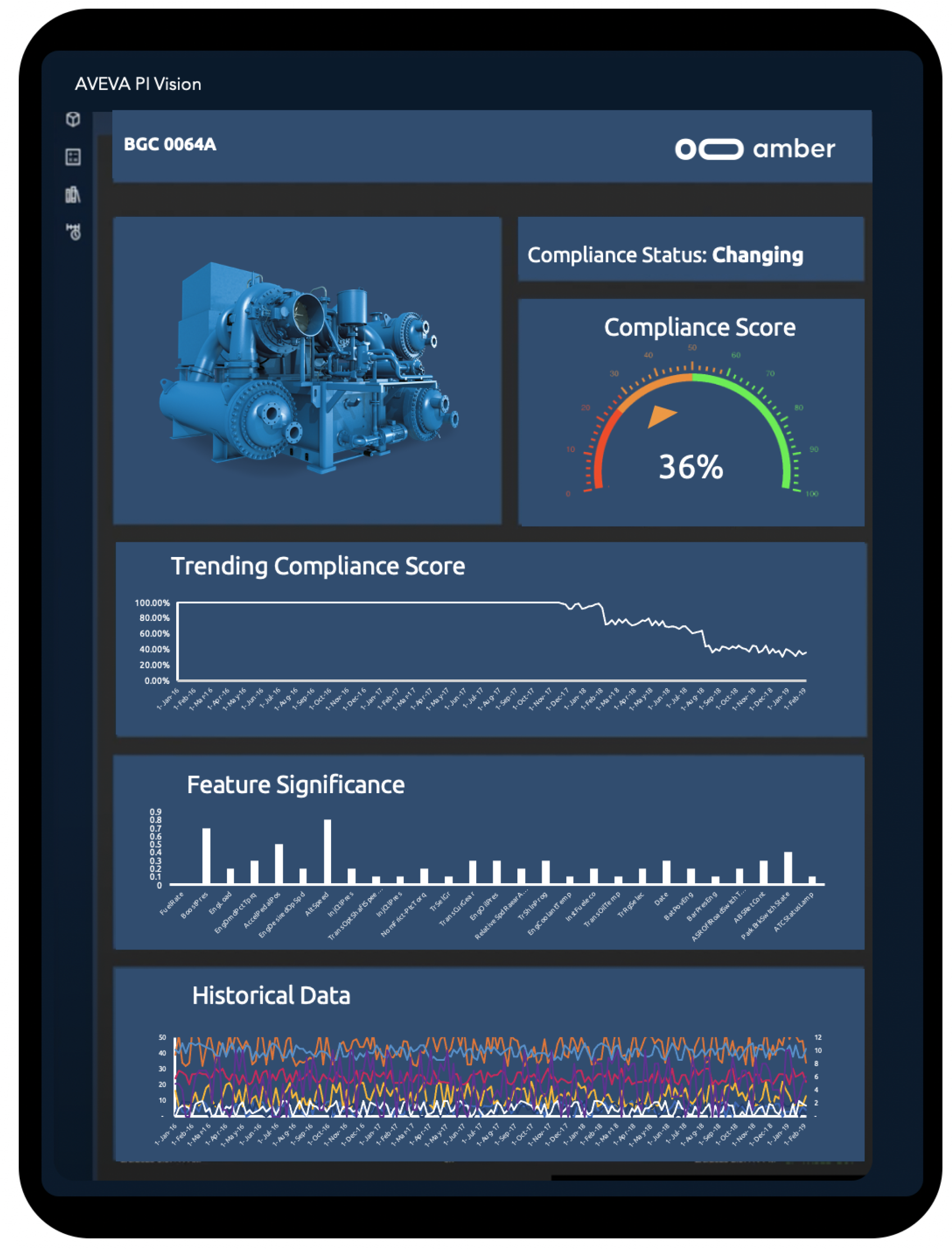
Easy to use
ML designed to be configured by reliability engineers and plant staff

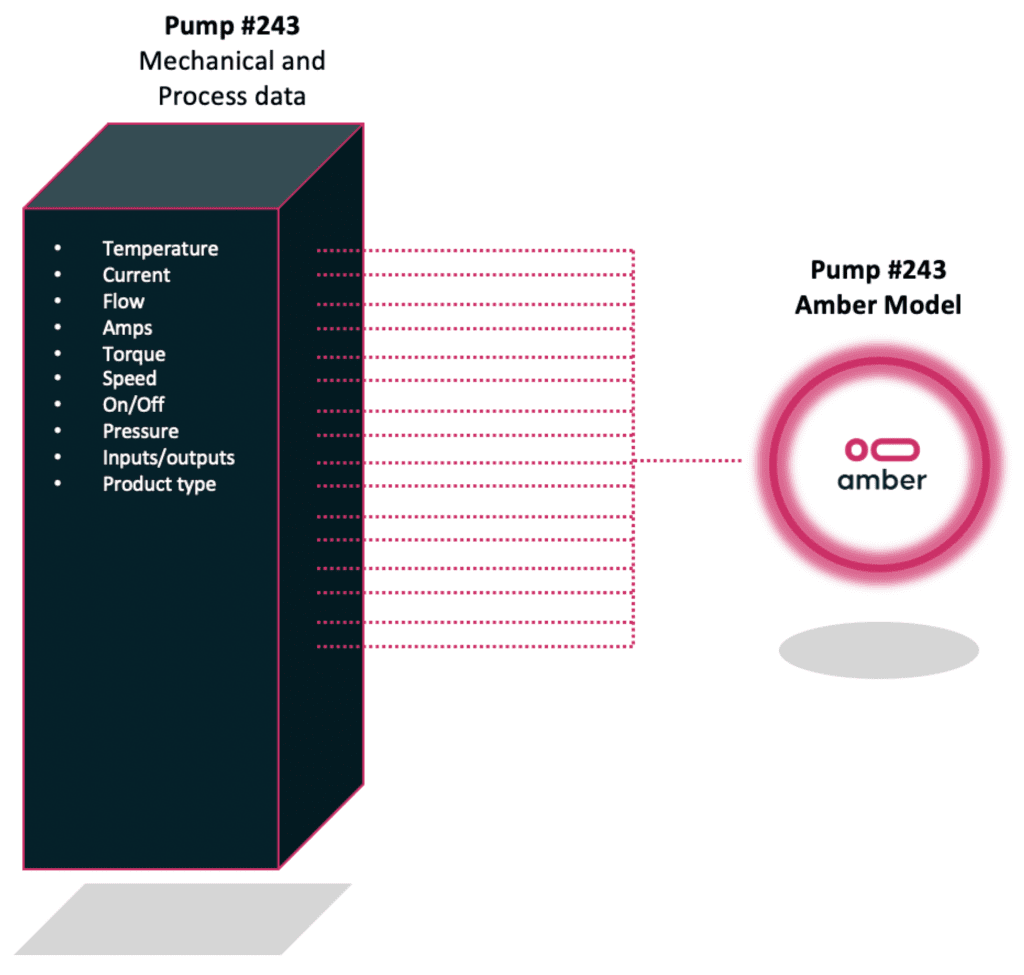
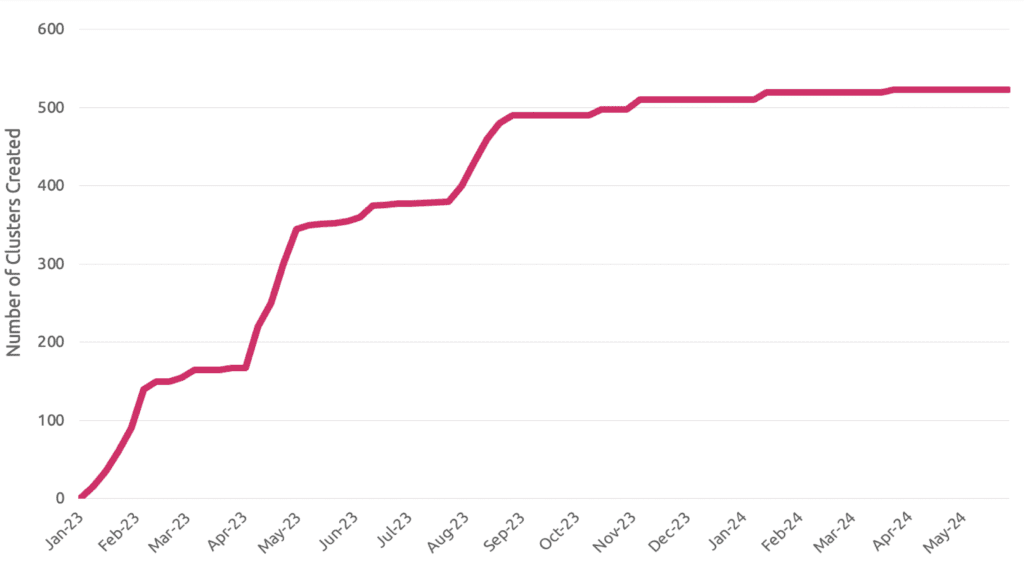
Quick to scale
Deploy thousands of models in weeks
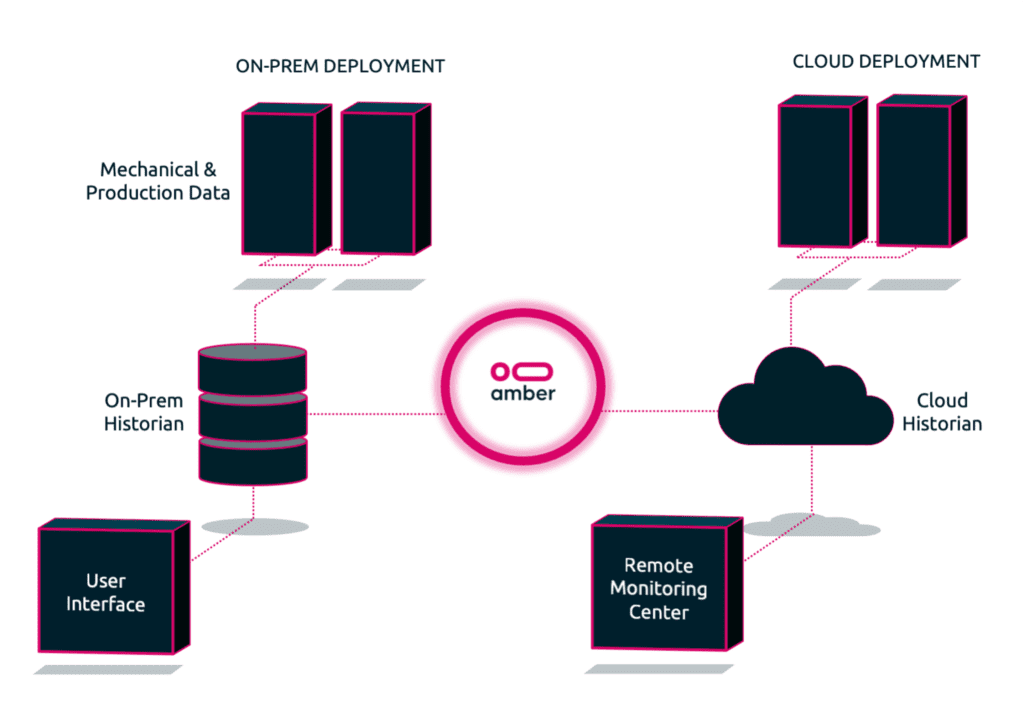

Native integration with PI Web API

Native integration with Ignition REST API

Native integration with Azure Event Hub

Native integration with Cumulocity




