
In a previous blog, What’s Wrong with Preventative Maintenance?, we described the limitations of PM schedules for reducing downtime and maintenance costs. In response to these limitations, a new real-time, data-driven approach seemed to be what was needed for reliability teams to tailor their maintenance strategy for each individual asset. In this blog, we’ll see the value of this approach and the new issues it created for large scale deployments.
What is pervasive sensing?
Data-driven, asset-specific, condition monitoring in any industry begins with pervasive sensing. This means for each asset you must collect up-to-the-minute asset telemetry, of which there are two types: sensor measurements and control parameters. Sensor measurements come directly from the high-value assets to be monitored and describe the true state of the asset in real time.
For example, vibration is considered to be the most valuable sensor measurement for rotational assets, and temperature, pressure, flow rate, and current are also useful. The second type of asset telemetry is control parameters such as RPM, desired temperature, desired pressure, and device mode settings. These “set points” define the asset’s configured state and can be compared to the asset’s actual measured state.
Many high-value assets already have multiple types of sensors preinstalled, and vendors also offer a variety of sensors that can be retrofitted to assets already in production. Ongoing sensor measurements are fed into OT networks via protocols such as MQTT and OPC UA, and asset control parameters can be harvested from PLC tags and fed into the same data pipelines. Next, these values cross from the restricted OT network (via firewall) into an IT network. Sensor measurements and control parameters for each asset are correlated via timestamp and are typically stored in a local and/or cloud database.
“What are we going to do with all this data?!”
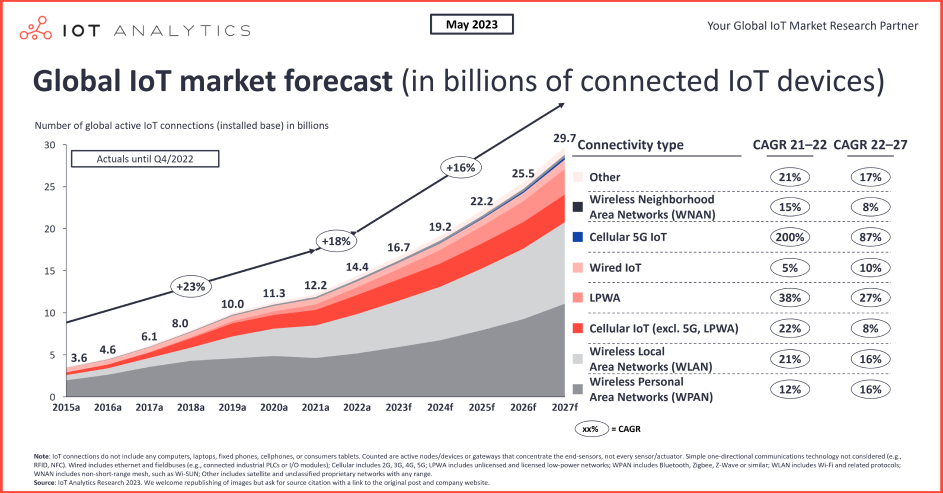
With these data pipelines running 24/7, it is easy to see that a single company can collect 100s of gigabytes or even multiple terabytes of asset telemetry in a single day. In 2027, according to IoT Analytics, it is estimated that there will be 29 billion IoT devices connected online.
Following the metaphor of vapor in a cloud condensing to rain that falls into a lake reservoir, the early idea of data storage “in the cloud” eventually transitioned to “data lakes” when it was realized that the virtual cloud cannot support long-term storage and rapid access of the petabytes of data collected over years of asset operation. It is amusing that now the term “glacier storage” is coming into currency as even data lakes are too costly to maintain. A different problem arises as data formats in the lake multiply and become non-standard from project-to-project, notoriously referred to as a “data swamp”.
Here we come to the crux of the matter: How does your company derive value from massive
amounts of asset telemetry collected by pervasive sensing? Here are three answers, each with its own major drawbacks.
Forensic Analysis: Following the failure of an asset, its telemetry can be investigated to look for clues of the developing non-compliance that eventually led to the failure. As this blog series is about predictive maintenance strategies that can prevent costly down-time, we’ll assume that you’re expecting far more from your asset telemetry than a post-mortem report.
Display it on a dashboard: There are some types of asset non-compliance that can be identified by an engineer who is looking at the time course of the asset telemetry on a web-based condition monitoring dashboard. The engineer may notice odd spikes in asset telemetry or an upward drift of a particular sensor reading that will indicate some developing problem. The shortcoming of this approach is clear: “What are we going to do with all of these dashboards?!”
For round numbers, let’s assume that a site has 100 pumps, each with 10 sensors. No one can monitor all of this asset telemetry. One approach we have seen from customers is that each morning someone is tasked with visually checking each dashboard for each asset to see if “anything looks off”. This is a rather disappointing place to end up after a company has completed their pervasive sensing journey.
Data Science to the Rescue?: If an engineer looking at a dashboard can see that an asset sensor value looks wrong, then clearly there are data science techniques that would allow the normal behavior of the asset sensor telemetry to be modeled so that significant deviations can be detected automatically and alerts sent to maintenance teams. This is a good approach, but even this is fraught with danger.
For example, The model development approach must be scalable (in terms of data scientist time) to hundreds of assets.
The ongoing model usage cost must be economical in terms of compute cost and model maintenance (yes, asset predictive models must be maintained just like equipment).
The analytical approach used must be very accurate (low false alert rate and high detection rate).
Of the many, many data science approaches available (classical statistics, Bayesian statistics, machine learning, physics-based modeling, to name a few), most are hampered by the inability of a single model to provide predictive value except for the specific asset data from which it was trained.
Universal models and transfer learning remain an impossible dream due to the complexity of asset telemetry relations that exist for high-value assets having complex operational patterns. As a result, each company’s data scientist pool struggles to build and maintain models for hundreds of assets.
To complete the value proposition of pervasive sensing, the industry needs a machine-learning based approach that can autonomously train a custom model for each asset. This is Amber.


