
Introduction
This blog explores the differences between supervised and unsupervised machine learning, the ideal applications for each, and the challenges of using supervised machine learning for the visual inspection of difficult-to-inspect injectable products.
Leading automated visual inspection manufacturers are moving toward AI-enhanced visual inspection to improve defect detection. However, the vast majority of manufacturers rely heavily on supervised machine learning (SML)., a less effective option than unsupervised machine learning (UML).
Differences Between Supervised and Unsupervised ML
At their core, supervised and unsupervised machine learning represent two fundamentally different approaches to teaching a machine how to interpret and act on data. The choice between these approaches significantly impacts the system’s ability to detect unknown defects and adapt to changing manufacturing conditions.
Supervised Machine Learning
SML relies on labeled datasets to learn how to map input data to specific output labels, making it ideal for tasks where the desired outcome is predefined. For example, in a visual inspection system, images of pharmaceutical vials are labeled as “defective” or “non-defective,” and the model learns to associate certain visual patterns with each label. This explicit training process allows SML models to predict outcomes for new data based on patterns learned during training.
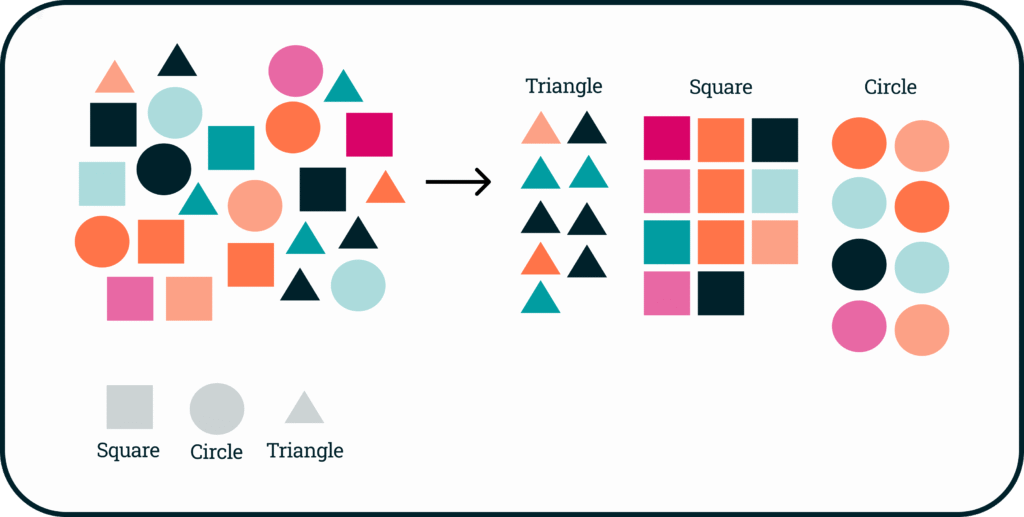
Unsupervised Machine Learning
In contrast, UML operates without labeled data and instead focuses on discovering patterns, clusters, or structures within the input data. Rather than being told what to look for, an unsupervised model analyzes data from a pre-inspected set of compliant items. The model identifies relationships and groupings that might not be obvious to a human observer. For anomaly detection, UML looks for deviations from what it determines to be “normal” based on the natural characteristics of the data.
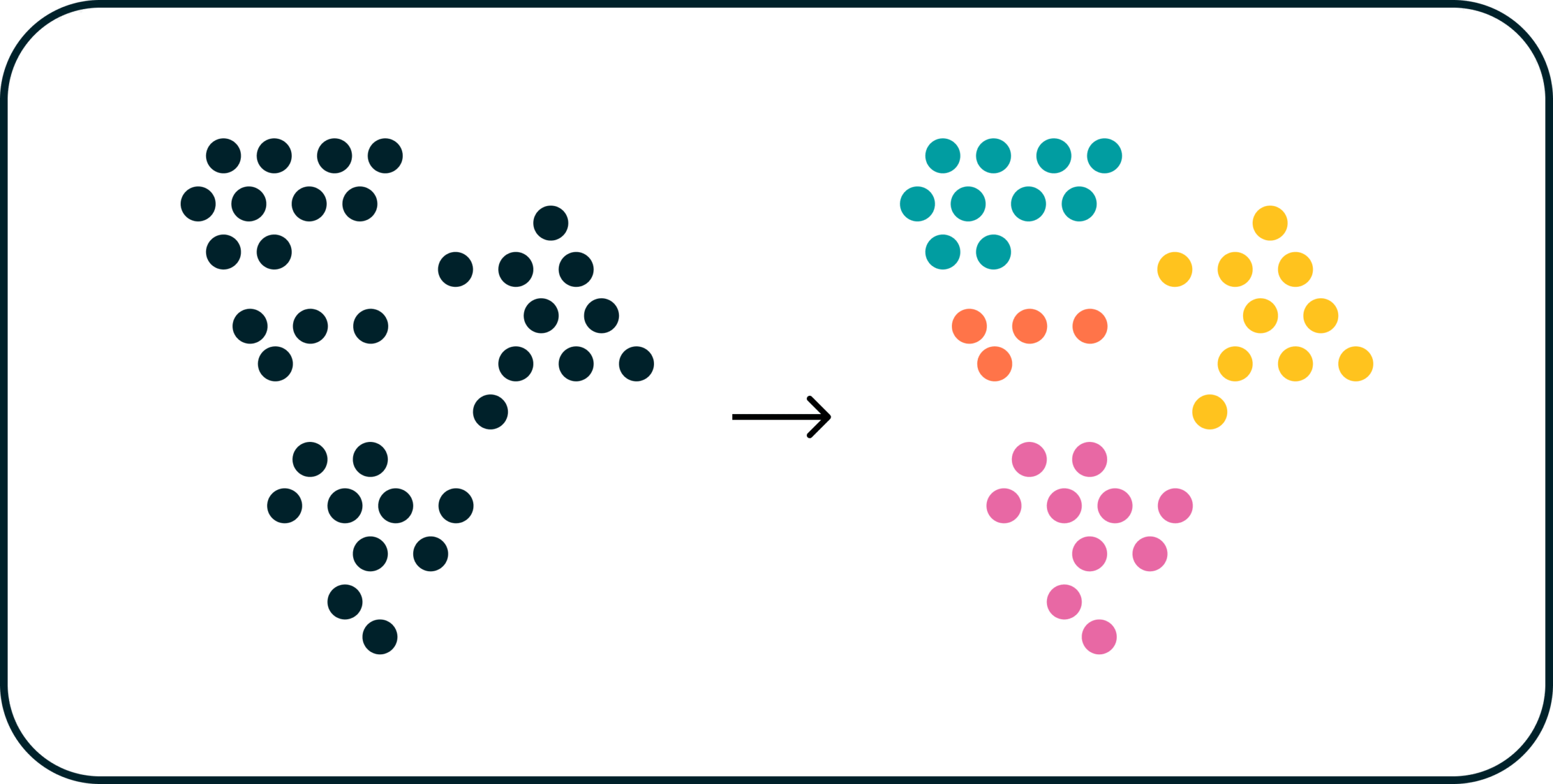
The primary distinction, therefore, lies in the learning process. SML requires explicit instruction and prior knowledge about what constitutes an anomaly, while UML learns directly from the data without preconceived notions of what is “normal” or “abnormal.”
Best Applications for Each
Supervised ML is best suited for scenarios where the goal is to classify predefined or labeled anomalies or defects. This approach shines in environments where specific defect types are known and categorized.
Unsupervised ML, on the other hand, stands out in environments where unknown or emerging anomalies are a concern. Instead of looking for specific defect categories, it models what a normal product looks like and flags anything that deviates from that model as an anomaly. This makes it ideal for complex, variable production environments where new, unforeseen defects may emerge over time.
Challenges of Using SML for Anomaly Detection
While SML can be highly effective under the right conditions, it faces significant limitations when applied to anomaly detection in dynamic environments.
One major challenge is its reliance on pre-labeled datasets. Supervised models can only detect defects they have been explicitly trained to recognize. For instance, a visual inspection system may be trained to identify cracks and particulates. But what if a new type of defect—such as subtle discoloration, slight label misalignments, or missing stoppers—appears? These new defects would not match any patterns the model learned during training, rendering it ineffective.
This reliance on prior knowledge severely limits the model’s ability to adapt. In pharma, where manufacturing processes and materials may change over time, the emergence of new defects is not uncommon. A model that can’t adapt to new defect types becomes a liability and an operational bottleneck.
Another challenge is the resource-intensive training process. Building an effective SML model requires collecting large volumes of labeled data. Labeling data is labor-intensive and costly, particularly in high-stakes industries where accuracy is critical. Moreover, once trained, these models are not easily adaptable. Changes in production or the introduction of new product lines often require re-collecting and re-labeling new datasets, further hindering operations.
Because of these challenges, SML models often fail to keep pace with innovation and the variability seen in modern manufacturing environments.
Benefits of Unsupervised Machine Learning
UML offers significant advantages when it comes to anomaly detection in complex, regulated industries like pharma.
First, UML does not require labeled datasets, significantly reducing the time and cost associated with data preparation. Instead of being explicitly trained on what a defect looks like, the model learns what normal products look like and flags anything that doesn’t fit the established pattern.
This ability to detect unknown anomalies is critical in environments where new defect types are likely to arise. By focusing on deviations rather than predefined categories, unsupervised models provide a more flexible and adaptive solution.
Getting the Best of Both Worlds
Because UML doesn’t rely on labeled datasets, it can identify both known and unknown defects, making it exceptionally well-suited for dynamic environments where new or rare anomalies may arise. This ensures that no anomaly—even one never seen before—slips through the cracks. However, SML can be used to add value through the categorization and labeling of the detected anomalies. Once UML flags a deviation, human inspectors can assign labels to these anomalies.
Over time, this process builds a structured, labeled defect library. SML models can then be trained on this library to accurately classify future anomalies into specific defect categories.In this hybrid model, unsupervised ML remains the backbone for anomaly detection, while the addition of supervised ML creates a more powerful and insightful inspection process.
